


A couple of weeks back, I wrote a post in the aftermath of CMLS Kansas City in which I mused out loud about things that were left unsaid, and said this:
So the clear implication is that everything in real estate is ultimately a zero sum game.
If an agent leverages technology, smart lead management, and topnotch service to increase production from selling 20 homes to 50 homes, then other agents in her market will be doing 30 fewer transactions. A broker making $100M more in revenues has to get that from somewhere — other brokers, from higher agent splits, somewhere. They don’t affect supply and demand; only macroeconomics does.
Similarly, if a vendor in the real estate industry becomes successful, that success must come from somewhere. It has to get a larger share of the Commission Pool, which necessarily means that someone else has to get a smaller share.
I then wondered who is walking around now with a target on their backs.
Well, an answer arrives by way of a post on the CMLS Blog by Michael Wurzer, CEO of FBS, and a Director of RESO. He writes to advocate for a Universal Property ID and says that RESO is working on creating the framework for creating and finding the UPID. Which sounds great, actually, but then he writes this:
Imagine for a minute if all of these entities worked together to create a Universal Property ID framework so that the framework would constantly learn and improve itself. That type of cooperation is very powerful and has the potential to create win-win scenarios for everyone, instead of just being satisfied with zero-sum games.
Yep, that “zero-sum games” was a link to my post, which made me wonder if maybe I failed to express my concept clearly enough. So let’s dig into this a bit, and why it is that I think this post actually clarifies who is feeling the pressure.
Who’s Down With UPID?
Michael’s concept (and therefore, the concept of the UPID Workgroup, I’d imagine) is that by creating a single unique ID for every piece of property (sort of like a VIN for every car?), we would find it extremely simple to share data about that unique property and to store data about that unique property. After all, the VIN is why Carfax can work as every insurance claim, every repair job, etc. is tied to that VIN.
Seems like a fine idea, and frankly, one that sounds like it’d take oh… about 15 minutes to do should one of the large parcel-centric guys (RPR? Zillow? Corelogic? Bueller? Bueller?) decide to share their numbering conventions, seeing as how they must have already done it. What’s interesting, however, is the language that surrounds the UPID. Michael writes:
Importantly, cooperating on such a framework does not require anyone to give up their proprietary databases. Upstream and RPR can continue to build their repository, as can MLSs, Zillow, Corelogic, and many others. The beauty is that, despite competing with their proprietary data repositories, Universal Property IDs provide a common way to connect the data when desired and authorized. Each competitor will continue to assert their unique advantages for their customers, resulting in no one repository becoming a 100% complete and accurate source of property data, but the UPID framework provides the potential to link all the data together. [Emphasis added]
Ah-ha! But what’s this about no one repository becoming a 100% complete and accurate source of property data? Well, above that paragraph, Michael writes this:
Central to the framework [of UPID] is the reality that there are many sources of property data and that each brings with it a different level of accuracy and confidence. Because there are so many different property data sources today, an industry-wide and cooperative effort like RESO is critical to defining and promoting adoption of the framework.
It’s starting to make sense now.
Under Pressure
I have nothing but nice thoughts about UPID; seems like a fine idea. I hope RESO gets to it real soon. The subtext of that post, however, makes it clear who is (or at least feels like they are) walking around with a giant target on their back: the MLS vendor.
How could they not? RPR isn’t just Upstream; it’s also AMP — the Advanced Multi-List Platform. It represents a huge leap forward in the actual technology that the MLS uses to provide its services to subscribers and Participants. It’s a parcel-centric database, which means that “adding a listing” is as simple as changing the status on a property and slapping an Asking Price on it. (With a few other fields, I guess, all relating to the marketing of the property as a listing for sale.)
Yes, true, RPR has not yet finished building any kind of a “front end” to an MLS… although anyone who has ever logged into RPR as it exists today should recognize that it’s pretty darn good:
Furthermore, I don’t have a crystal ball or anything, and I haven’t traveled back from the future to be able to say with certainty, but I’ll bet a month’s worth of income that whatever front-end RPR comes up with will not feature error messages like this one that still pops up on current MLS systems in 2015:
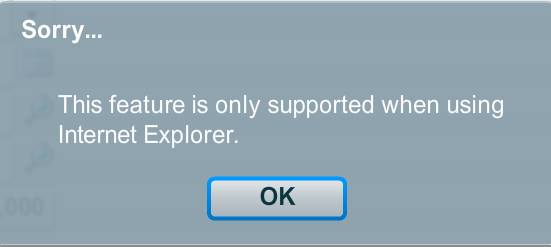
Now, Upstream likes to talk a lot about “feeding data into the MLS” using RESO standards and specs. But the entire thing is much, much simpler and easier to do if the MLS is already on RPR AMP. Then, there’s no data feed, because the MLS is using the exact same parcel-centric property data that Upstream will be using. Change the status in Upstream, and voila, it magically changes in the relevant MLS if it’s on AMP.
Imagine that you’re the CEO of an MLS where many of your largest and most important brokers are dues-paying members of Upstream. Your MLS vendor contract is coming up for renewal. Which system would you — and more importantly, the Technology Committee of your Board that is staffed by volunteer brokers and agents — find the most compelling?
Since I’m no longer working with/for RPR, I have no idea if this linkage will be made as Bob Bemis, the new VP of Business Technologies, will go around pitching the adoption of AMP to sundry MLS organizations… but um, knowing Bob, and knowing he’s a very intelligent, very savvy, very with-it executive, I have little doubt that the feature-not-a-bug will be pointed out to MLS boards everywhere. (At a minimum, he’ll at least think about it after having read this post….)
In light of these known facts… I guess the existing MLS vendors have chosen to compete on the basis of some sort of unspecified unique advantage that accrues to the customer MLS due to proprietary databases. I don’t know what those things might be, but then, I haven’t really studied the subject. Perhaps someone more versed in the arcana of databases could explain just what kinds of benefits and advantages accrue to an MLS, to a broker, or to an agent from having a proprietary database.
Of course, if the future of the MLS remains a landscape of a bunch of proprietary databases (conveniently sold and managed by the existing crop of MLS vendors + RPR), then UPID is absolutely necessary.
So, About that Zero-Sum Game
What I don’t understand is why that scenario of proprietary databases + UPID results in a win-win for everybody instead of the diabolical zero-sum game a la Notorious Rob.
See, my point about the Zero-Sum Game of Real Estate is that the industry does not affect the housing market; only macroeconomic factors affect the housing market. Ergo, the total amount of commission dollars available to literally everyone connected to the real estate industry from RPR to MLS CEO salaries to broker profits to agent take-home pay to the virtual assistant in Bangladesh is completely independent of what the real estate industry does or does not do.
A win-win scenario a la Wurzer in which existing MLS vendors keep their proprietary databases up and running, while making room for RPR to do AMP and Upstream, is a win-win for those two entities only. Somebody has to pay the bill for those companies to stay in business, whether that somebody is the MLS or the broker or the agent or some other set of vendors or whatever. Anytime one company in real estate makes money, that money has to come from the pool of commissions over which the industry has no control.
This isn’t me knocking the vendors or RPR or any project or concept or what-have-you. It’s simple logic. UPID can neither convince a single homeowner that he should sell his family home nor magically convert an unemployed Millennial performance artist into a buyer who can qualify for a mortgage. So the money to pay for all this wonderful stuff has to come from somewhere, and more precisely, from someone.
Collaboration Is Definitely One Way….
Which then raises the issue of collaboration. There is something touching and uplifting and inspiring about the real estate industry sanctification of the Holy C-word: Collaboration. At CMLS Kansas City, I was actually tempted to start a drinking game during the final panel in which we’d all have to do a shot every time some panelist mentioned collaboration or collaborative or cooperation. Had that game happened, there may have been alcohol poisoning at the event given how often the Holy C-word was mentioned by every single panelist.
So it seems natural to a real estate industry insider that when there are “so many different property data sources today” what is absolutely necessary is “an industry-wide and cooperative effort.” Whereas, I learned my ABC’s of business from the worlds of retail, finance, law, and Internet companies, and therefore am afflicted with deep cynicism (some might call it “realism” or “common sense”). So I feel like there is actually an entirely different solution to the problem of “so many different property data sources.”
That solution is the age-old one practiced by such non-collaborative pricks like Julius Caesar: Conquest.
If the existence of “so many different property data sources” is the problem, the solution could be eliminating all the different property data sources. Screw collaboration; conquer them instead. And then, once conquest is done or at least well underway, whoever is the winner can come out with — you guessed it — the Universal Property ID which is identical to the Property ID they’re already using.
Contrary to the slogans of the peaceniks, war is not only the answer, it is often the most effective answer.
The post by Michael Wurzer, representing the viewpoint of the existing MLS vendor community, which happens to include some of the largest, most powerful, and most influential technology companies in our industry, is appealing to the Collaborative Angels within real estate to stave off what at least they see as the obvious threat: that RPR Upstream/AMP will eliminate the need for so many different property data sources such that collaboration is not only unnecessary but actually undesirable for RPR and its supporters.

Upstream eliminates the need for brokerages to have so many different property data sources. AMP eliminates the need for the 850+ MLSs to have so many different proprietary databases — at least if the “unique advantages” of such proprietary databases do not outweigh the benefits of belonging to the Data Borg. And in a Zero-Sum Game world, it seems to me that one clear benefit of the Data Borg would be cost savings for everyone involved, as they transfer a portion of the dollars spent on these proprietary databases and the vendors who provide and manage them to the Data Borg, and pocket the rest.
Can it really be doubted that the MLS vendors feel like they have a target on their backs?
Don’t Worry, Be Happy
Having delivered a vision of civil war within the real estate technology space, let me say that actually, while this is all kind of interesting as an intellectual and writing exercise for your humble scribe, I’m somewhat not worried about all of this.
Conflict can lead to real progress. Already, ever since the May announcement of RPR Upstream/AMP, we have seen a flurry of activity on the part of MLS vendors. Corelogic has introduced Trestle, and I’m certain that other vendors are hard at work on something new and cool and useful to try to compete against RPR. Some might embrace radical new strategies we haven’t seen yet to remain relevant in the upcoming age, while others may step up their customer service game. Hey you know, we might even see an end to silly error messages like the one above about needing Internet Explorer. One can even dream and think that we might see MLS user interfaces and front-ends that don’t look like they were designed by blind misanthropic rhesus monkeys.
Ultimately, all this competition, all this conflict, will result in better products and better services for the MLS, for the brokers, and for the working agents on the street who need better tools and better technology to keep up with ever-smarter, ever better informed buyers and sellers. Sure, we might lose a company here or there along the way, and we might see conquest by the Data Borg — or we might not. Along the way, though, we’ll see dramatic improvement in technology for less money. That’s how these things work.
And that’s a win-win in a zero-sum game: a win for the conquerors, and a win for the customers.
-rsh


19 thoughts on “Win-Win In A Zero-Sum Game”
So here’s a problem: the UPID isn’t like a unique, known identifier (the VIN analogy), a UPID is more like an API disguised as data, effectively serialized data (things you know about a property — the address, a geocode, county parcel identifier) and it’s up to the vendors to de-serialize, compare to their internal data and match based on varying confidence of how well those fields match.
Another problem, one alluded to by Mr Wurzer in his post, is that counties are constantly adding, splitting, merging, renumber/reformat parcel ids, change addresses on properties, etc. Add in the fact that all of these various vendors with their proprietary databases update at varying frequencies necessitates the UPID approach instead of the more logical VIN-style unique id. I was talking to Jeremy Crawford from RESO at CMLS, discussing UPIDs, and another guy came up, explained what they used, a VIN-style unique id. We use a similar method internally, I’m sure every vendor has their own approach but it’s not really the same thing as the UPID. UPID is more a matching technology than an explicit identifier.
That kind of gets back to the idea of proprietary databases — each has their own quality level (timeliness, completeness, amount of detail) and each may have their regional strengths and weaknesses. That’s why there will continue to be that competition and why while a national database sounds nice it may ultimately be a loss at the local level.
Thanks for the clarification. As I said, I don’t have any issue with the UPID idea per se. Pretty sure it’s useful. But I’m saying there is an alternative to “That kind of gets back to the idea of proprietary databases — each has their own quality level (timeliness, completeness, amount of detail) and each may have their regional strengths and weaknesses. That’s why there will continue to be that competition and why while a national database sounds nice it may ultimately be a loss at the local level.”
When you conquer all these little regional proprietary databases, then there won’t be variations on quality level or what-have-you. And in a zero-sum game scenario, the question is going to be whether what you lose by getting rid of the regional database (timeliness, etc.) outweighs what you gain by the Data Borg.
That is, if the difference between a proprietary regional database and the Data Borg is 3 days of “timeliness”, then yes, it makes sense to keep the former. If the difference is 3 *minutes*, then no.
The whole post is actually about Collaboration vs. Conquest. We assume far too often in RE that “various vendors with their proprietary databases” updating at varying frequencies is a given, which then means we have to collaborate. I’m saying it’s a perfectly valid strategy to simply eliminate the various vendors, which then removes the need to collaborate. 🙂 And that seems far more like the broader approach of Upstream/AMP at least at this point in time.
The difference between the databases isn’t 3 minutes vs 3 days, it’s 3 weeks or 3 months or even a year or more in certain cases when you’re integrating non-MLS data to try to get to your canonical list of all properties in the country. Remember, properties are constantly being created and destroyed and renamed by local city and county officials who publish the results in their own ways and on their own timelines. There’s all sorts of things that make the whole process messy without even considering the quality of the data — I’m just focusing on having a list of the properties that exist as a starting point. How much new construction is added to an MLS without corresponding data from the county assessor? Or maybe the street doesn’t exist yet according to the city/county/USPS because of publishing lag? How do I know the listing is a real property with a real address and not a typo or error or something more nefarious without that digital confirmation of a national property database? That’s kind of step 0 of this whole process of having a national database – first you must be an authority that can acknowledge that a property exists and has specific characteristics like a verified address.
You can’t just be RPR (or anyone else) and by fiat decree that their dataset is the new canonical database because you’re going to be missing things, there are going to be errors and there is going to be confusion and conflict about all of those things that needs methods for resolution. I don’t believe that you can say that we’ve got 3 or 4 proprietary national datasets and the way to solve it is to create another proprietary dataset*. It’s the same model just a different master. You’re just not going to get a comprehensive database the way you would with more interested parties engaged in maintaining the data, effectively using the crowd-sourced approach to data somewhat on the lines of the way projects like OpenStreetMaps work. They end up doing a lot of bulk imports and reconciling of data from multiple sources and have a good handle on things like transaction history for edits. Something like that at least acknowledges you’re working with a live database and takes into consideration multiple owners and editors of that data. I don’t know how you could or would get buy in for a project like that but it’s really without that cooperation any attempt to create a national database is going to be at best incrementally better than where things are now.
* see https://xkcd.com/927/
Thanks Jeff for the explanation. It makes me an even bigger fan of the UPID project now. 🙂
At the same time… don’t think it really addresses the core point, which is that enough people (a) think the Data Borg can be established, and (b) want to be the Data Borg. We shall see.
But again, fantastic explanation of the issues! Thank you.
{quote} I don’t know how you could or would get buy in for a project like that but it’s really without that cooperation any attempt to create a national database is going to be at best incrementally better than where things are now.{quote}
Jeff, this is exactly the point I was making in my original post. The interesting thing about a UPID project is that it doesn’t even need to deal with all the attributes of every property, just enough to identify the property. Outside of a compilation, this type of data already is public, non-copyrightable information. In addition, all the stakeholders (consumers, brokerages, the NAR, MLSs, local, state, and federal governments, Zillow, etc.) would value the end result, which is a canonical source for property identification as it would improve everyone’s data sets.
Universal Property ID was already invented for us 2300 years ago by a guy named Eratosthenes. It’s called latitude and longitude.
– latitude and longitude can describe the center of a property
– latitude and longitude can describe the boundaries of a property
– latitude and longitude can describe entire subdivisions, PUDs, condominiums, anything real estate.
– latitude and longitude can describe if a property sits inside another property by using point-in-polygon calculations.
– latitude and longitude can apply to spatial places (like condos in high-rise buildings) when z-cordinates are used.
– latitude and longitude do not require a cloud server to always be up and running.
– latitude and longitude do not need some corporate opportunist in control of it and taking everybody else’s money.
This “UPID” scheme reminds me of Amazon’s invention of their product numbering system they call “ASINS”. Amazon invented the ASIN number to describe every single product or service that they offer. Then they fooled everybody into trusting them, and now when everybody shops online they think it has be be on Amazon (even though their price is almost always higher). Amazon conquested the zero sum game of eCommerce by taking more dollars for themselves while making smaller businesses struggle or close their doors.
So screw that. I’m no ore interested in some Amazon-like creature taking over the real estate industry with their “Universal Property ID” scam than I am Amazon coming in and assigning an ASIN to everybody’s property.
The Zillow / Trulia problem is already big enough. Don’t open a pandora’s box like this, or you’re going to have an Amazon problem, or a Walmart problem, or a Google problem on your hands.
Use latitude and longitude. It’s free, and it’ll go a long way in keeping dollars in your pocket and away from the big greed factories.
Interesting point about Amazon…
Seems to me that they were never all that interested in collaborating and cooperating with the thousands and millions of retailers. Instead they went with, “Our system is better, so we’re just gonna crush you” which then allowed them to create ASIN. Or Google, who wasn’t all that interested in collaborating with AskJeeves and Yahoo and Dogpile and all of those has-been search engines.
I don’t know much about the origins of Amazon so I can speak to exactly what their original plan was.
However, I can speak to the origins of Google, and when they came on the scene in 1998 they were the sweetie-pies of the search engine industry. While giants like Infoseek gave speeches shaking their fingers at search engine marketeers, Google gave presentations advocating for the entrepreneur, while boasting their company motto, “don’t be evil”. In the adoption years that followed until about 2005, Google went a long way in helping businesses earn success on their platform, but that changed after the Google IPO. They became more and more greedy – out for themselves. The rest is history as over the past two decades Google has become the same jerks that Infoseek once was. Now they are like a mama mocking bird squawking at any business that tries to get ahead without paying them. Around every corner is Google trying to insert themselves into your life, a staunch difference than the little submissive sweeties they were when the came on the scene in ’98.
Google is just an example. It doesn’t matter about whether you’re talking about Google, Amazon, Walmart, or Zillow. They are all greedy bastards that, at their core, don’t care about cooperating – not with competitors, and not with their customers either.
And back to point about UPID. Some greedy bastard will get a hold of it and try to crush people with it. The community came together to invent free php/mysql (php.net, mysql.com) when Oracle wanted to rip people off, the community came together to invent free Open Office (openoffice.org) when Microsoft tried to rip people off for Microsoft office. I hope the community will come together and realize that the free gift of latitude and longitude was given to them long ago. Latitude and longitude is UPID, and it’s free.
In my presentation at RESO, I talked about Walmart adopting an EDI (Electronic Data Interchange) standard in the 1990s. At the time many standards existed and Walmart was the largest emerging retailer. Everyone followed and all other standards went away. Fast forward to today, Amazon created its own standard for product identification to overcome duplication and product description inconsistencies. Traditional retailers are suffering meanwhile because they have store fronts and attempting to complete in e-commerce with Amazon. Walmart has a problem! I found this very short article on Wall Street Journal from April 2014 really cool to read: http://blogs.wsj.com/cio/2014/04/07/retailers-face-inconsistent-product-data-in-e-commerce-efforts/
e-mail me to request a copy if you don’t have WSJ subscription.
All very interesting Rob but I know we enjoy talking fashion more than any other topic. You missed my corduroy orange jacket at RESO 🙂
This link should get you to directly to the WSJ article mentioned by Ohan:
https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=newssearch&cd=4&cad=rja&uact=8&ved=0CCUQqQIoADADahUKEwi746Hi0-zIAhWBJiYKHfhvCrU&url=http%3A%2F%2Fblogs.wsj.com%2Fcio%2F2014%2F04%2F07%2Fretailers-face-inconsistent-product-data-in-e-commerce-efforts%2F&usg=AFQjCNHuSzoT9vBW9lG49usCo33RcKR5pg
This post got me thinking about the peripheral topics. Instead of UPID, I was taken by the Zero-Sum and Conquest ideas. Using NAR’s round numbers, once the conquest is complete, there are only 1 Million potential customers for MLS products and assuming that the DOJ doesn’t get cute about a monopoly and step in to break up the Mama MLS into Baby MLSs as it did with the telephone system, Technology Vendors will have to sell product desk by desk instead of region by region.
Some industry analysts point toward a natural continental market of perhaps 15 – 20 MLS Zones of Commerce. Even that will certainly put a big dent in the double dipping that keeps vendors in the current zero sum game as users will have far fewer reasons to access more than one MLS system.
How many MLS User accounts are there today? In my home state there are probably 2 or 2 1/2 times the number of MLS User accounts as there are actual users as people need access to neighboring systems.
Thanks Thomas! Love stimulating thinking about peripheral topics. 🙂 An excellent question, by the way, but let me stimulate the thinking a step further.
What if, instead of the DOJ getting cute about a monopoly and breaking it up, HUD *creates* the monopoly as a regulated utility? (Or even better, wait until the monopoly is created by the industry, then step in and take it over, as we’ve seen with student loans, with healthcare, and mortgage financing.)
Thank you for making the driest of subjects hilariously entertaining.
This might be my favorite compliment of all time. 🙂
Zillow’s property id’s have been publicly available for anyone to use via the API (which I ran from 2007-2010) since…2006.
I would just like you to know at least one person got the joke/pun you were making with the MK image.
Zero-sum game… sum… zero… Sub… zero…
Or maybe I’m just reading into it too much, lol.
Does anyone really believe that collaboration between all these entities will end up leading to a lower cost for the agent? I would venture to say the more layers added into the process will only make the whole thing more expensive vs the “regional” type mls system that exists today. It maybe a zero sum game for income side but does not seem to be on agent expense side.
Comments are closed.